At the end of this most recent January, I wrote Narrowing the Cone of Error, The Origin Story of a High Output AI Coding Workflow, a story about how I had built my AI development workflow. Things have evolved in the last month since I wrote that.
ADRs (Architectural Decision Records)
At the time when I wrote the article, I had seen previously seen people who had used ADRs in the course of building with AI to help it direct its action as it built to maintain design integrity. I knew NoteCove had a few places where Claude had been getting things wrong from time to time in the sync architecture that I’d have to fix. Given the information about ADRs I’d seen, it occurred to me that an ADR (or a set of ADRs) might be something to try as I had some upcoming work on NoteCove that would be adding things that needed sync support.
I took some documents I already had, and wrote a specific one about tenets about how the sync architecture should work. I had Claude create an index of the ADRs and added some stuff to /feature to consider the ADRs I had and see which ones might apply to compose the plan. Turned out that did exactly what I hoped, and the newly written code worked just as I had wanted it to.
ADR Audits
However, I knew there were some places that I hadn’t gotten around to fixing. It occurred to me: I should have Claude audit the code to find out where things diverge from the ADR I had about storage tenets. As it would happen, it not only found all the places I knew things weren’t right, but identified a few others, and then proceeded to fix them. Very nice! The prompt for the storage tenets was simply:
/feature In the ADR directory there is a doc called
@ADR/Storage_Implementation_Tenets.md that I want you to read, and then go
over the storage implementation for both ios and desktop and report back
places where what you see is not in alignment with what the doc specifies.
Also if the doc is unclear, let's work through those and improve the doc.
I thought it would be nice to be able to do this sort of as a unit test from time to time, but having an LLM in the loop for that seemed like the wrong fit. So for the moment, I put it away, and did other audits from the other docs I had.
Reviews
The notion of ADR audits brought me to the idea of reviews. While it’s pretty common to do code reviews as part of the normal AI flow, it doesn’t prevent the architectural coherence problem of systems. I’ve seen this happen with human generated code and code reviews over the 30 years of my career more than a few times. As a system grows over time, especially when growing quickly, it can have more the appearance of something that has congealed, rather than having a coherent design. In debugging a few parts of NoteCove, it became clear there were places in the code where architectural coherence was not where I wanted it to be.
To do this, I had Claude survey the entirety of the source code:
/feature Full systematic code review of the codebase. Look for:
- Duplicative code that should be common
- Abstractions that are too much or too little
- Race conditions, concurrency issues (especially CRDT/sync)
- Edge cases, off-by-one errors
- Error handling gaps
- Null/undefined safety
- Architecture and coupling concerns
- Maintainability (naming, dead code, unnecessary complexity)
- Security (input validation, injection, auth boundaries)
- Performance (N+1, hot paths, things that will blow up at scale)
- Tests that test implementation details vs meaningful behavior
Also: argue against the design and what would you do differently?
Output: a report that could be thrown at /feature to go fix things.
Additionally to that I made sure that I gave Claude the intent for the review, and what I was worried about, and the flavor of feedback I wanted.
This resulted in it finding 6 bugs, 8 architectural problems, 15 middling priority things, 15 low priority items, as well as some gems like this:
The SQL cache is doing too much manual work. Every CRDT write must be manually followed by SQL cache updates (extract title, extract tags, extract links, update FTS, etc.). This is error-prone — miss one extraction step and the UI shows stale data. The 4x-duplicated tag/link extraction (ARCH-7) is a symptom. Alternative: Treat the SQL cache as a materialized view that rebuilds from CRDT state. Have a single
materializeNoteCache(noteId, doc)function that extracts ALL derived data (title, preview, tags, links, task links, headings, FTS) and writes it all at once. This eliminates the N separate extraction steps and makes it impossible to forget one.
Here, it’s 100% right, and is something that should be addressed to reduce the chances that we’ll do something going forward that will fail to live update. So the audit pulled up much I knew about, and some I didn’t. Then it just remains to /feature the problems away.
About Those ADR Audits…
With some of the ADR audits, there are parts of it that are easy for Claude to get wrong, and it lurked in the back of my mind that I’d have to remember to do these audits every once in a while. While Claude has been great at referencing them when it’s appropriate, but something more sure would make me feel more comfortable. Because if there’s an oops, I have to hope it’s not been too long after the oops that I detect it, as the longer it remains, the more difficult I’ve found it to be to fix it.
Somehow I got the idea “I wonder if these ADR checks can be automated so they run at lint time, but without having Claude do it.” Turns out, a lot of them can, and more than you’d think. While some of them turned out to be simple grep checks, one of them I wound up having claude build a tool using the Swift AST library to do the check. Lints I would never have written as a human coder, I can now have Claude do.
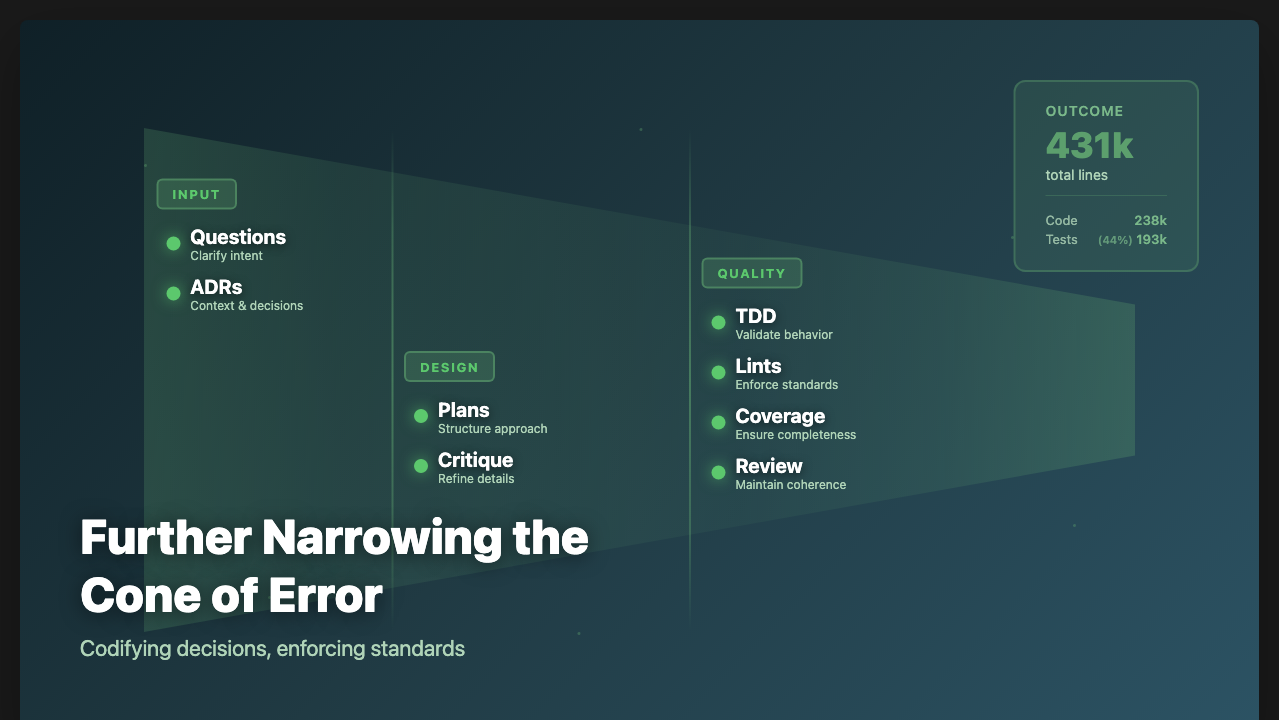
Summary
NoteCove development continues apace, now at 431k lines of code total (up 101k lines from 330k since the end of January) while keeping the percentage that is test LoC level at 44% (so 238k lines main, 193k lines of test). With more guardrails in place, I can maintain development velocity and have more trust that the guardrails will hold. Assuming current pace holds, I’ll have the first public beta for desktop by the end of the month (I’d guess about mid month), and maybe iOS with iCloud by the end of the month. I’ll be accepting requests for invites for it very soon now – website also coming soon!